tl;dr
- Bugs found in production cost 15-30x more to fix than those caught during design. This is documented across decades of research
- The “classic” development model pushes testing to late stages, creating expensive bottlenecks and unpredictable releases
- Shifting testing left through automation reduces costs, accelerates delivery, and improves quality simultaneously
- Three testing categories enable shift-left: fitness functions (architecture), automated development tests (code), and targeted UAT (validation)
- The investment in test automation typically delivers positive ROI through reduced defect remediation costs and improved team velocity
I’ve watched this scenario unfold at several organisations in several projects: a critical bug surfaces in production. The scramble begins. Developers drop everything, context-switch from their current work, reproduce the issue in a completely different environment, trace it through integrated systems, fix it, and pray the fix doesn’t break something else. Meanwhile, the planned release slips another week.
What if that same bug, caught three months earlier during development, would have cost the organisation 30 times less to fix?
I’ve seen this pattern repeat itself across different teams, different tech stacks, and different industries. It wasn’t until I dug into the research (from Barry Boehm’s foundational work at TRW to IBM’s Systems Sciences Institute studies) that I realised this wasn’t just bad luck or poor execution. The data from four decades confirms what I’d observed firsthand: the later you find a defect, the costlier the fix.
The Economics of Defect Detection
The IBM Systems Sciences Institute research established what’s now known as the “1-6-15” rule: a bug found during implementation costs approximately 6x more to fix than one found during design. By the testing phase, that multiplier climbs to 15x. In production? Up to 30x or more.
Now, I’ll admit these ratios emerged from waterfall-era studies, and I’ve had developers argue they don’t apply to modern agile teams. But here’s what I’ve observed: whilst continuous deployment and feature flags can reduce the detection lag, they don’t eliminate the cost differential. Even in teams deploying multiple times per day, a defect caught in code review still costs far less than one discovered by customers. The speed of your deployment pipeline doesn’t change the fundamental economics.
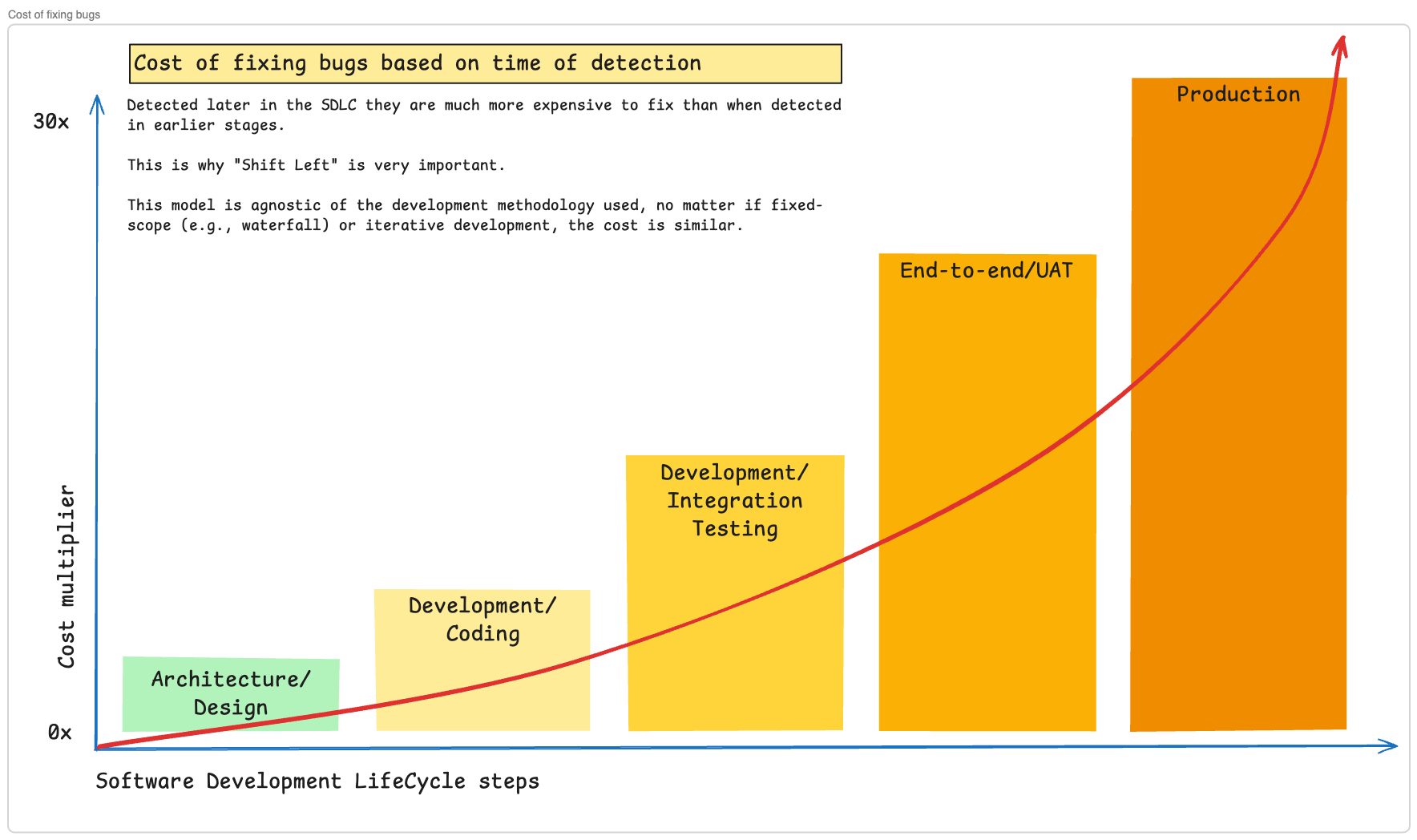 Cost escalates exponentially as defects move through the SDLC. A £100 fix during design becomes a £3,000 problem in production. This model is agnostic of development methodology, the cost curve is similar.
Cost escalates exponentially as defects move through the SDLC. A £100 fix during design becomes a £3,000 problem in production. This model is agnostic of development methodology, the cost curve is similar.
Let me break down why this happens, because it’s not just about the fix itself. When I’ve tracked the true cost of production defects, here’s what I’ve found organisations are actually paying for:
- Direct costs: Developer time to reproduce, diagnose, fix, and verify. QA time to retest. DevOps time to make an emergency deployment. This is the visible part.
- Indirect costs: The hidden killer. Research by Gloria Mark at UC Irvine shows context switching can cost 23 minutes before developers regain full focus. I’ve watched entire sprint commitments unravel because three production incidents scattered the team’s attention. This translates to delayed features and, eventually, low team morale.
- Business costs: Customer impact. Support tickets. In regulated industries, potential compliance issues. The 2002 NIST study estimated software defects cost the U.S. economy $59.5 billion annually (approximately £100 billion in 2025 terms). Having worked with financial services and healthcare organisations, I can tell you the problem has only intensified.
The Classic Model: Testing as an Afterthought
Most organisations still operate under what I call the “classic” development model. It looks similar to this image:
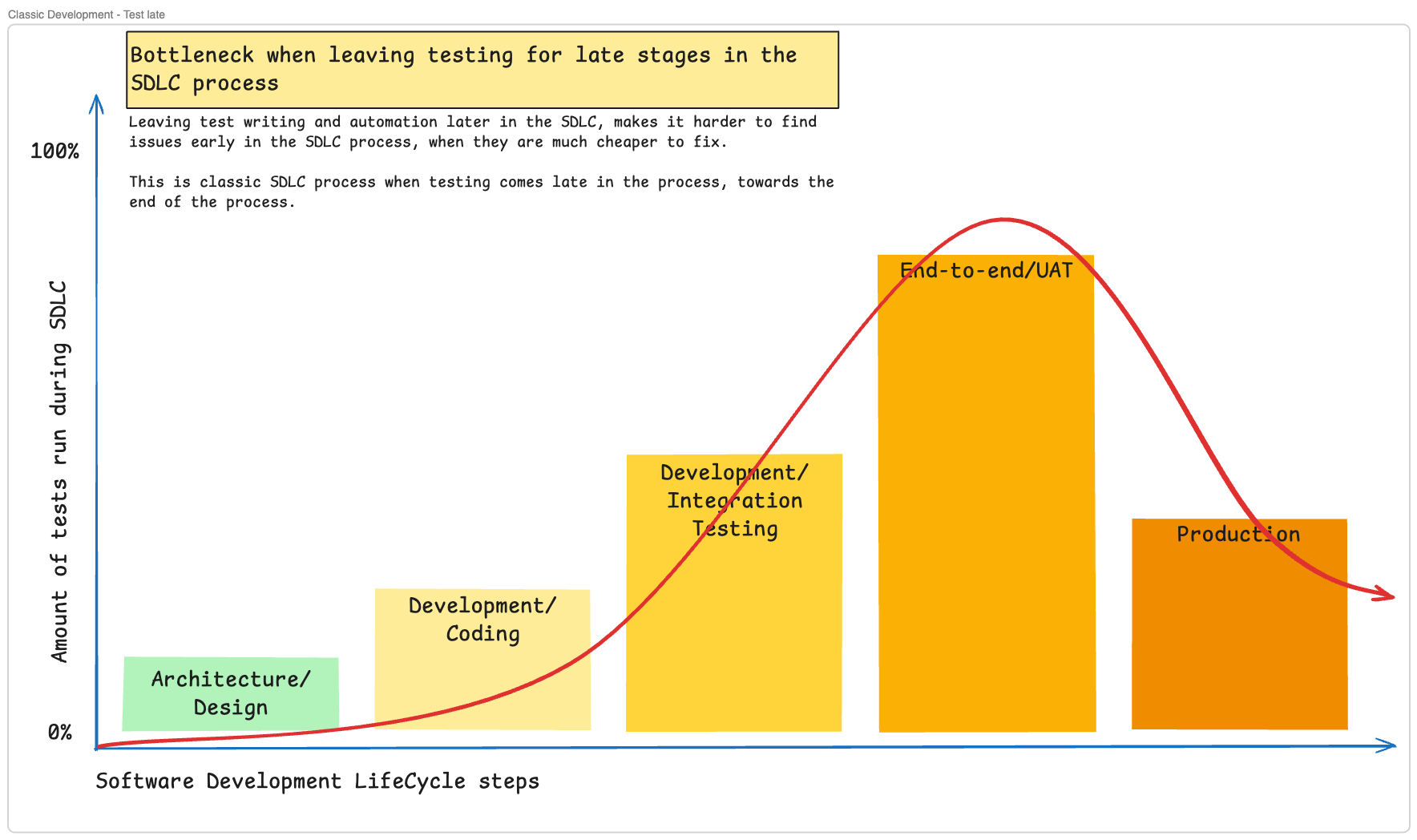 When testing volume peaks late in the cycle, you’ve created an expensive bottleneck. This is the classic SDLC process where testing comes toward the end.
When testing volume peaks late in the cycle, you’ve created an expensive bottleneck. This is the classic SDLC process where testing comes toward the end.
I’ve consulted for organisations where this is still the dominant approach. Development teams write code, hand it off to testing/QA team(s), and then wait to discover what’s broken. This late stage usually coincides with where most of the delays from earlier stages have accumulated, making the pressure to meet go-live deadlines even more intense. The result? I can predict it before I even see the project plan:
- Bottleneck at UAT: All the defects that could have been caught earlier pile up at the end. I’ve sat in uncomfortable meetings where project managers are forced to choose between shipping with known defects or missing the deadline by months.
- Unpredictable releases: When you don’t know how many defects exist until late in the cycle, you can’t reliably forecast when you’ll ship. I’ve watched teams push release dates back three, four, sometimes six times.
- Firefighting culture: Teams become reactive rather than proactive. Engineers spend their days addressing yesterday’s production incidents instead of building tomorrow’s features. In the organisations I’ve observed, this unplanned work can consume up to 30% of engineering capacity.
- Budget creep: Here’s a painful pattern I’ve seen repeatedly: the development stage gets marked as “completed”, the development team moves on to other projects. Then UAT discovers critical defects. Now the organisation needs to hire the development team back, often at premium rates, whilst the deadline pressure keeps mounting.
Why Organisations Don’t Shift Left (Even When They Should)
If the ROI is so compelling, why do many organisations still test late? Seeing and helping several engineering teams through this transition, I’ve found the resistance is rarely irrational. There are real barriers:
- Upfront investment before returns: Shift-left requires building test infrastructure, training developers, and changing workflows before you see cost savings. For teams under delivery pressure, “invest now, benefit later” is a hard sell to leadership focused on quarterly commitments.
- Developer resistance: Many developers see testing as QA’s job, not theirs. Writing tests feels like overhead that slows feature delivery. This perception is wrong, and changing it requires cultural work, not just tooling.
- Legacy codebase challenges: Retrofitting tests onto a 1,000,000-line codebase with no existing test coverage is genuinely expensive. The architecture may not even support unit testing without significant refactoring. Teams look at the mountain and conclude it’s not worth climbing.
- Short-term delivery pressure: When leadership measures success by features shipped this quarter, investing in test automation that pays off next quarter feels like a losing trade. The incentive structure often works against long-term quality investment.
- The “we’ve always done it this way” inertia: The classic model is familiar. People know their roles. Changing it means uncertainty, and uncertainty feels risky, even when the current state is objectively more expensive. This is a hard one to change if the people you are working with are not open minded and embrace change as part of their day-to-day activity.
- Budget: I’ve seen several places where the way budgets are set makes it difficult to embed testing into early stages of the SDLC. Usually, they have a hefty budget and long timeline allocated for testing towards the end of the project. Shifting part of the budget and time early in the SDLC feels unnatural to some places. I am still to understand why.
These barriers are real, but they’re not insurmountable. The key is acknowledging them honestly rather than pretending shift-left is a simple tooling change.
The Shift-Left Alternative
When I first encountered the term “shift-left”, it sounded like consultant jargon. But after implementing it across several teams, I’ve come to appreciate its simplicity: move testing activities earlier in the development lifecycle. Instead of testing being something that happens to code after it’s written, testing becomes integral to how code is written.
The principle is straightforward: find defects where they’re cheapest and fastest to fix.
But here’s what I’ve learned: implementing shift-left requires more than good intentions or a motivational all-hands presentation. It requires specific types of tests at specific phases of development, each designed to catch particular categories of defects. Let me walk you through what’s actually worked for the teams I’ve guided.
Phase 1: Architecture and Design - Fitness Functions
Before a single line of production code exists, you can validate architectural decisions through fitness functions. I first encountered this concept in Neal Ford, Rebecca Parsons, and Patrick Kua’s Building Evolutionary Architectures, and it transformed how I approach system design. These are automated checks that verify your system maintains its intended architectural characteristics.
What I’ve used fitness functions for: Ensuring systems continue to meet non-functional requirements as they evolve: performance thresholds, security boundaries, coupling limits, and compliance constraints. They act as guardrails against architectural drift.
Why they’ve saved me from expensive mistakes: Architectural mistakes are the most expensive to fix, and I’ve seen both sides of this. Discovering your database can’t handle projected load during design? That’s a manageable architecture revision. Discovering it six months after launch, with customers affected and the press writing about your outages? That’s a crisis that can end careers.
Who owns them: In the teams I’ve worked with, the architecture/system design team owns these.
When they run:
- Continuously, as part of your CI/CD pipeline.
- Every code change is validated against architectural constraints automatically.
Phase 2: Development - Automated Unit and Integration Tests
During active development, automated tests provide immediate feedback on code correctness. This is where I’ve seen the shift-left investment deliver the most dramatic returns.
What unit tests have accomplished for teams I’ve worked with: They verify that individual components behave correctly in isolation. A well-designed unit test suite catches logic errors, boundary conditions, and regression issues within seconds of introduction. My rule of thumb: test behaviour, not implementation. Focus on business logic, not on framework implementation or boilerplate code (I’ve reviewed too many test suites that meticulously tested getters and setters whilst missing actual business rules).
What integration tests accomplish: They verify that components work together correctly. They ensure your service communicates properly with its dependencies and that data flows correctly through the system. Here’s a warning from hard experience: these tests require ongoing investment. I’ve watched flaky or outdated integration tests erode team trust faster than no tests at all. Budget for maintenance from day one.
Why they’ve saved teams enormous cost: A failing unit test during development costs minutes to diagnose and fix. I can identify the problem, fix it, and verify the fix before my coffee gets cold. That same defect, discovered during UAT? Now I’m reproducing the issue in a different environment, potentially across multiple integrated services, coordinating with multiple teams. What was a 10-minute fix becomes a 2-day investigation.
Who owns them: The development team. Full stop.
When they run:
- Unit tests on every save or commit.
- Integration tests on every pull request or merge.
Phase 3: Pre-Release - Targeted UAT
User Acceptance Testing still has a role, but in the shift-left models I’ve helped implement, it’s no longer the primary defect-discovery mechanism. Instead, UAT validates that the system meets business requirements and handles real-world usage patterns. The emphasis here is on business requirements and nothing else.
What UAT accomplishes in this model: It catches the defects that automated tests can’t anticipate: usability issues, workflow problems, and those edge cases that emerge from actual user behaviour. I’ve seen UAT testers discover issues that made perfect technical sense but completely failed to match how users actually work.
Why it’s “targeted”: Because automated tests have already filtered out the obvious bugs. In teams I’ve worked with, UAT has transformed from spending 80% of their time filing basic defect reports (“the login button doesn’t work”) to doing meaningful exploratory testing and business validation. This is what good QA engineers actually want to do.
Who owns them: A dedicated testing team, though I’ve seen successful models where product owners are heavily involved.
When they run:
- Before major releases, with a scope appropriate to the changes being deployed.
The Inverted Pyramid
When shift-left is implemented effectively, the testing distribution inverts:
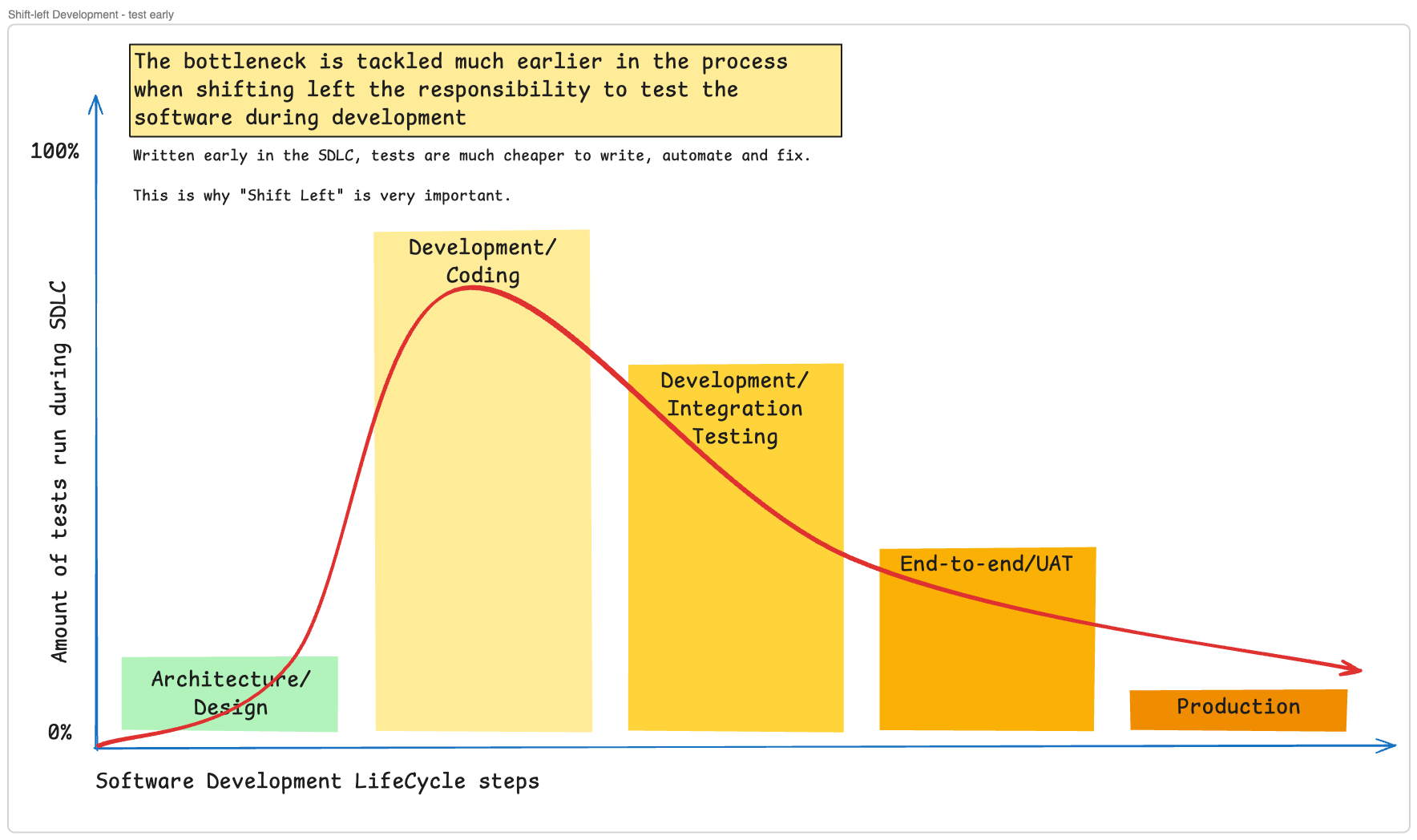 Testing volume is highest during development, when defects are cheapest to fix. Written early in the SDLC, tests are much cheaper to write, automate, and fix.
Testing volume is highest during development, when defects are cheapest to fix. Written early in the SDLC, tests are much cheaper to write, automate, and fix.
The majority of testing happens during development, automatically. UAT becomes a validation gate, not a discovery phase. Production monitoring provides safety nets, not primary defect detection.
When Shift-Left Doesn’t Make Sense
Before I convince you to invest heavily in shift-left testing, let me be honest about when it’s not the right approach. We shouldn’t apply shift-left dogmatically, as there are some legitimate exceptions:
- Prototypes and throwaway code: You might spend more time writing tests for a prototype than building the actual prototype. Build it, learn from it, throw it away.
- Very early-stage startups: If you’re pre-product-market-fit and your primary risk is building something nobody wants, shift-left might eat from your initial time-to-market window. The exception: if you’re in a regulated industry or handling sensitive data, you can’t skip this step.
- Spike solutions and research: Same as for prototypes. Do the research, gain the knowledge, then apply shift-left principles to the production implementation.
- Low-risk, low-change components: A static content page that displays your company address doesn’t need the same testing rigour as your payment processing system. Apply your testing investment where the risk justifies it.
- Very small, short-lived projects: Same as for prototypes. Sometimes good enough really is good enough.
The key is being intentional about your choices. Don’t skip testing because you’re too busy or it feels like overhead. Skip it when the business context genuinely doesn’t justify the investment. And be honest with yourself about which situation you’re actually in.
The Business Case for Investment
Transitioning from classic to shift-left requires investment in several areas:
- Test automation infrastructure: CI/CD pipelines, test environments, and tooling.
- Team capability: Developers who write tests alongside code. QA engineers who design test strategies rather than execute manual test scripts.
- Culture change: Quality as a shared responsibility, not a phase after development “finishes.”
Let me be direct about the transition cost: Your velocity will temporarily decrease. Teams learning to write tests alongside code will ship fewer features in the first quarter or two. Developers will grumble about the overhead. Some will leave. Leadership will question the investment when the next quarterly review shows less progress.
This is the valley you must cross. Organisations that abandon the transition halfway, after incurring the costs but before realising the benefits, get the worst of both worlds.
But here’s why the ROI is still compelling:
- Cost avoidance: If 30% of your production defects could have been caught during development, and production defects cost 30x more to fix, you’re looking at substantial savings. For a team that spends £500K annually on defect remediation, catching even half those defects earlier represents over £200K in direct cost reduction.
- Velocity improvement: Teams who don’t spend 20-30% of their capacity on production firefighting ship more features. The same team, with fewer interruptions, delivers more value.
- Predictability: When defects surface early, release dates become reliable. When releases are reliable, the business can plan around them.
- Less budget creep: There are fewer chances for expensive bugs to make it into production and to require expensive fixes.
- Retention: Engineers prefer building new capabilities to debugging production issues. Reduced firefighting improves team satisfaction and reduces turnover.
A Step-by-Step Transition
Having guided organisations through this transition, I’ve found a phased approach works better than a big-bang transformation. Here’s the sequence that consistently succeeds:
Step 1: Establish the foundation
Before writing a single test, ensure every code change triggers an automated build. Set up a CI pipeline if you don’t have one. Invest in stable test environments as tests are only valuable if they run reliably. I’ve seen organisations undermine their entire shift-left initiative with shared, unstable environments that produce intermittent failures. This seems basic, but I’ve seen organisations try to implement test automation without reliable builds and that doesn’t work.
Step 2: Start with new code only
Require tests for all new features and bug fixes going forward. Don’t attempt to retrofit the entire legacy codebase. The goal is building the habit while keeping the scope manageable. Resist the temptation to mandate 80% coverage overnight. Imposing unrealistic limits will only slow the team down (sometimes to a grinding halt) as they try to retrofit tests into a codebase that’s often not even suitable for testing, much less doing it quickly.
Step 3: Identify your riskiest components
Every codebase has high-risk areas (e.g., the payment processing module, the authentication system, the core business logic). Add test coverage there first. You’ll get the highest return on your testing investment and demonstrate value quickly. You will also make these high-risk components less susceptible to bugs.
Step 4: Introduce integration tests
Once unit testing is habitual, add integration tests that verify component interactions. This catches a different class of defects, the ones that emerge when systems connect.
Step 5: Define fitness functions for architectural constraints
What response time is acceptable? How many external dependencies can a service have? Codify these rules and run them on every commit. This prevents architectural drift before it becomes expensive to reverse.
Step 6: Retarget UAT
With automated tests catching functional defects, UAT teams can focus on what humans do best: exploratory testing, usability evaluation, and business validation. This isn’t downsizing QA, it’s elevating their contribution to actually look into quality assurance and not into manual testing.
Step 7: Measure and iterate
Start measuring, track trends and adjust. Track defect escape rate (defects found post-development divided by total defects). Monitor mean time to detection. Watch velocity trends. These metrics prove the ROI and identify where to invest next.
The timeline varies by organisation size and technical debt level. Small teams with greenfield projects might complete this in several months. Large enterprises with decade-old codebases might take several years. The sequence matters more than the speed. Even if it seems like a huge effort, don’t give up.
The Bottom Line
The pattern is consistent across every place where I observed this behaviour: testing late is expensive. Every defect that escapes to production represents a cost multiplier: in developer time, in business impact, in opportunity cost.
Shift-left testing isn’t about testing more. It’s about testing at a different moment, under different constraints: catching defects when they’re cheap to fix, automating the repetitive, and focusing human attention where it adds the most value.
The investment required is real. The transition is uncomfortable. But the organisations that push through emerge with faster delivery, more predictable releases, and engineering teams that ship features instead of fighting fires.
Not in Scope
When reading this article, many people might ask the questions of “what is a unit test” or “what is an integration test” etc. I intentionally didn’t introduce these definitions in this article as every time the answer is “it depends”. This sounds a lot like a consultant, and every team and organisations has their own constraints that actually contribute to their definition so I will let everyone reading this article to define those based on their use-case.
Glossary
SDLC: Software Development Life Cycle: the structured process for planning, creating, testing, and deploying software.
Shift-Left Testing: Moving testing activities earlier in development to catch defects when they’re cheaper to fix.
Fitness Functions: Automated tests verifying architectural characteristics (performance, security, scalability) remain within acceptable bounds.
Unit Tests: Automated tests verifying individual components work correctly in isolation.
Integration Tests: Automated tests verifying multiple components work correctly together.
UAT: User Acceptance Testing - testing by end-users to verify the system meets business requirements.
CI/CD: Continuous Integration/Continuous Delivery - automated building, testing, and deployment of software changes.
References
- Barry W. Boehm. Software Engineering Economics
- IBM Systems Sciences Institute. Relative Cost of Fixing Defects - Business Systems Planning Guide (1981)
- National Institute of Standards and Technology (NIST). The Economic Impacts of Inadequate Infrastructure for Software Testing - Planning Report 02-3 (2002)
- Neal Ford, Rebecca Parsons, Patrick Kua, Pramod Sadalage. Building Evolutionary Architectures
- Gloria Mark, Victor M. Gonzalez, Justin Harris. No Task Left Behind? Examining the Nature of Fragmented Work - Proceedings of CHI 2005
- Gloria Mark, Victor Gonzalez. The Cost of Interrupted Work: More Speed and Stress - Proceedings of SIGCHI 2008
- Synopsys. Cost to Fix Bugs and Defects During Each Phase of the SDLC
- Richard W. Selby. Software Engineering: Barry W. Boehm’s Lifetime Contributions to Software Development, Management, and Research